 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJames F. Allen
A Language for Planning with Statistics
Mar 20, 2013
When a planner must decide whether it has enough evidence to make a decision based on probability, it faces the sample size problem. Current planners using probabilities need not deal with this problem because they do not generate their probabilities from observations. This paper presents an event based language in which the planner's probabilities are calculated from the binomial random variable generated by the observed ratio of one type of event to another. Such probabilities are subject to error, so the planner must introspect about their validity. Inferences about the probability of these events can be made using statistics. Inferences about the validity of the approximations can be made using interval estimation. Interval estimation allows the planner to avoid making choices that are only weakly supported by the planner's evidence.
Identifying Discourse Markers in Spoken Dialog
Jan 17, 1998
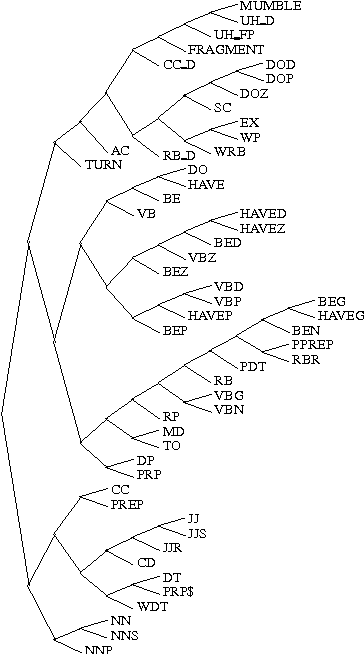
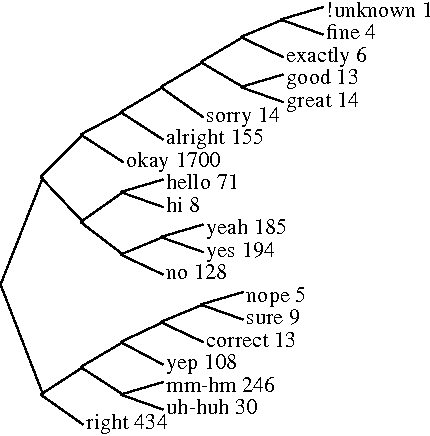
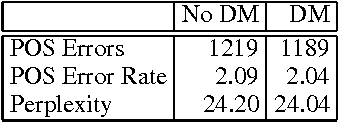
In this paper, we present a method for identifying discourse marker usage in spontaneous speech based on machine learning. Discourse markers are denoted by special POS tags, and thus the process of POS tagging can be used to identify discourse markers. By incorporating POS tagging into language modeling, discourse markers can be identified during speech recognition, in which the timeliness of the information can be used to help predict the following words. We contrast this approach with an alternative machine learning approach proposed by Litman (1996). This paper also argues that discourse markers can be used to help the hearer predict the role that the upcoming utterance plays in the dialog. Thus discourse markers should provide valuable evidence for automatic dialog act prediction.
* 8 pages, uses psfig
Incorporating POS Tagging into Language Modeling
May 22, 1997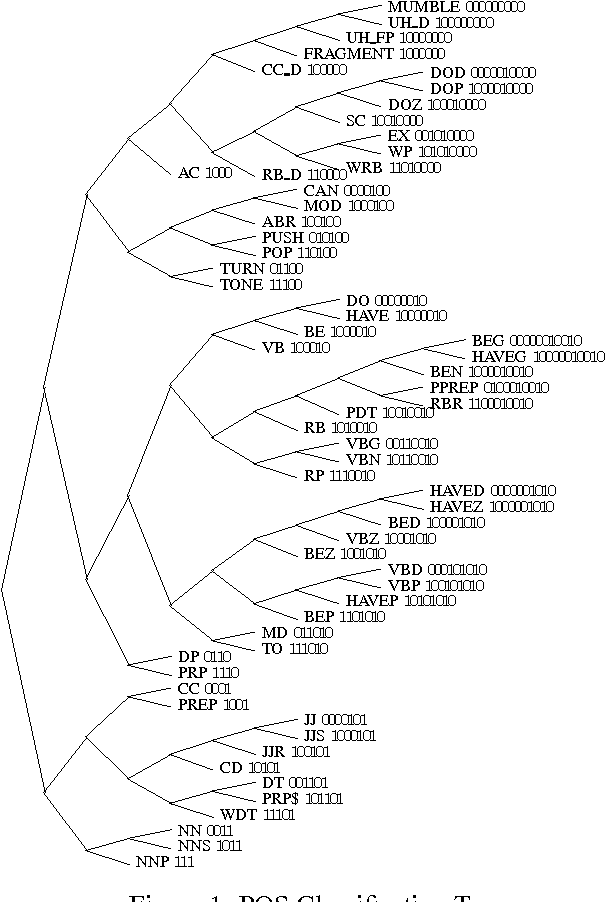
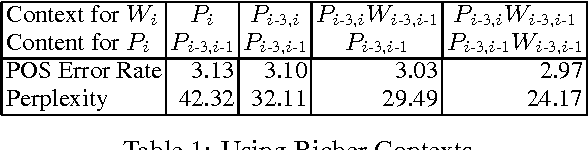
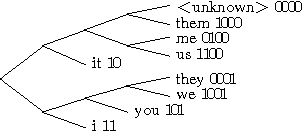
Language models for speech recognition tend to concentrate solely on recognizing the words that were spoken. In this paper, we redefine the speech recognition problem so that its goal is to find both the best sequence of words and their syntactic role (part-of-speech) in the utterance. This is a necessary first step towards tightening the interaction between speech recognition and natural language understanding.
* 5 pages, 2 postscript figures
Intonational Boundaries, Speech Repairs and Discourse Markers: Modeling Spoken Dialog
Apr 23, 1997
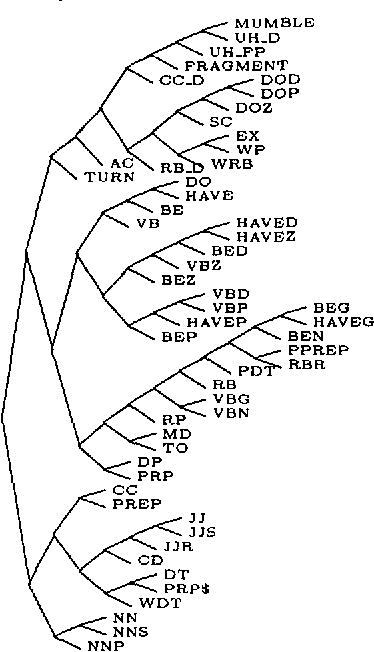
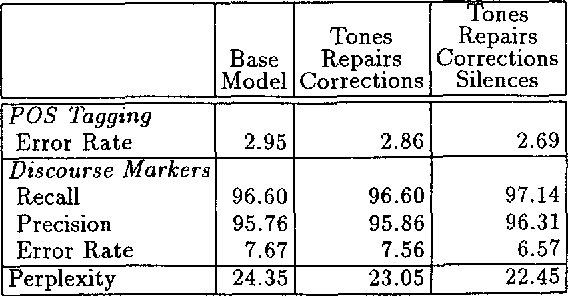
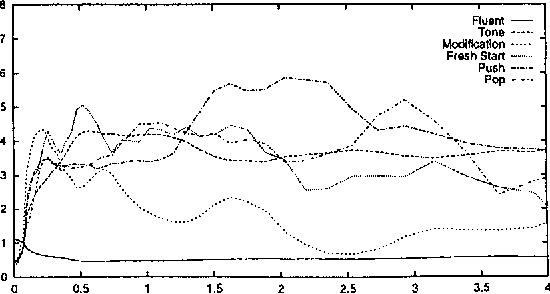
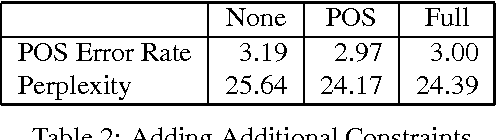
To understand a speaker's turn of a conversation, one needs to segment it into intonational phrases, clean up any speech repairs that might have occurred, and identify discourse markers. In this paper, we argue that these problems must be resolved together, and that they must be resolved early in the processing stream. We put forward a statistical language model that resolves these problems, does POS tagging, and can be used as the language model of a speech recognizer. We find that by accounting for the interactions between these tasks that the performance on each task improves, as does POS tagging and perplexity.
* 8 pages, 3 postscript figures
A Robust System for Natural Spoken Dialogue
Jun 18, 1996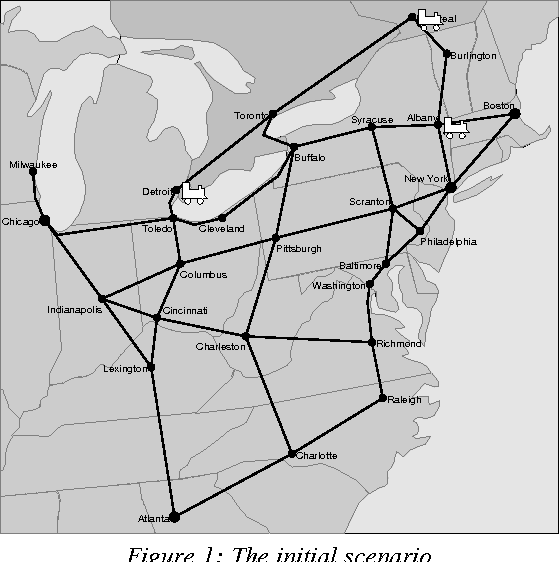
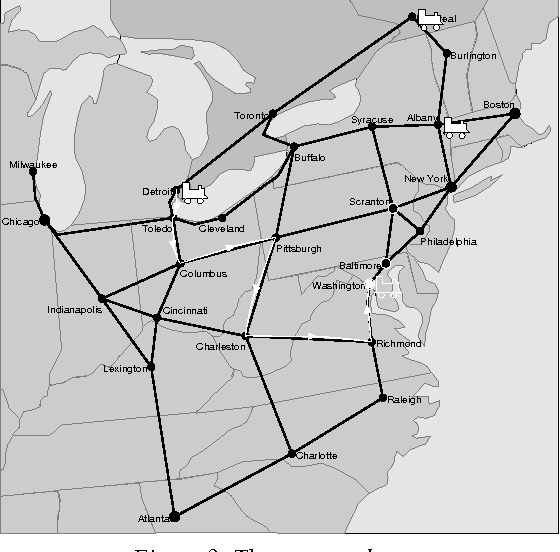
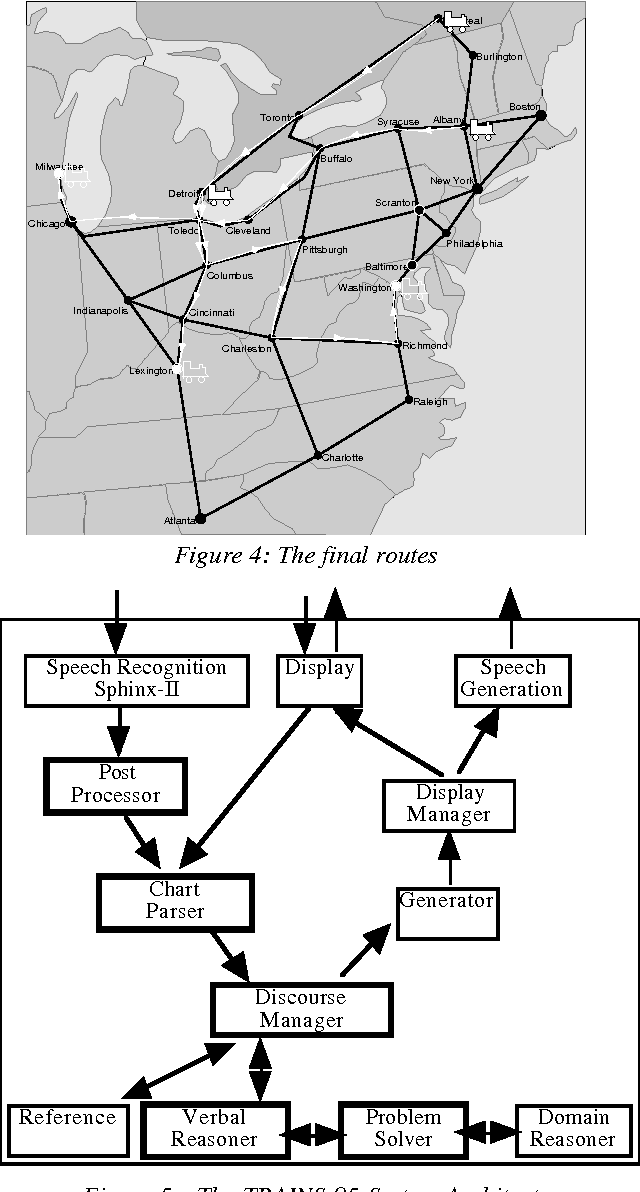
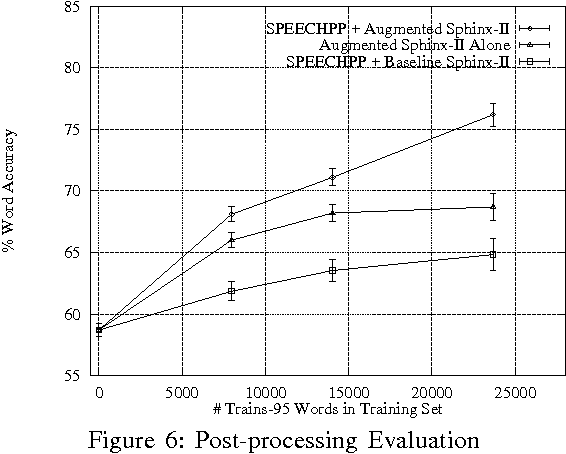
This paper describes a system that leads us to believe in the feasibility of constructing natural spoken dialogue systems in task-oriented domains. It specifically addresses the issue of robust interpretation of speech in the presence of recognition errors. Robustness is achieved by a combination of statistical error post-correction, syntactically- and semantically-driven robust parsing, and extensive use of the dialogue context. We present an evaluation of the system using time-to-completion and the quality of the final solution that suggests that most native speakers of English can use the system successfully with virtually no training.
* uuencoded, gzipped PostScript. Includes extra Appendix
Discourse Obligations in Dialogue Processing
Jul 14, 1994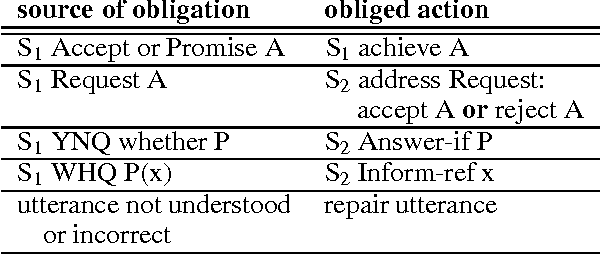

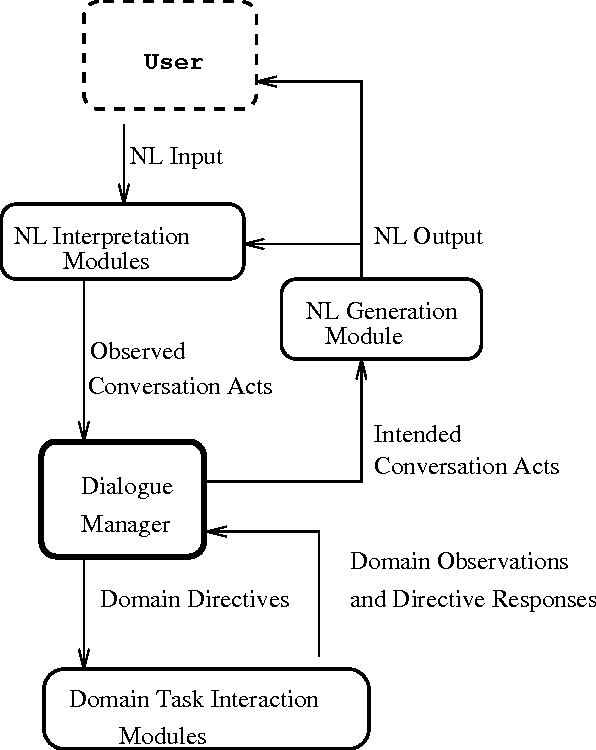

We show that in modeling social interaction, particularly dialogue, the attitude of obligation can be a useful adjunct to the popularly considered attitudes of belief, goal, and intention and their mutual and shared counterparts. In particular, we show how discourse obligations can be used to account in a natural manner for the connection between a question and its answer in dialogue and how obligations can be used along with other parts of the discourse context to extend the coverage of a dialogue system.
* 8 pages